代码拉取完成,页面将自动刷新
下面以BiSeNetV2和医学视盘分割数据集为例介绍PaddleSeg的配置化驱动使用方式。如果想了解API调用的使用方法,可点击PaddleSeg高级教程。
按以下几个步骤来介绍使用流程。
在使用PaddleSeg训练图像分割模型之前,用户需要完成如下任务:
# PaddleSeg的代码库下载,同时支持github源和gitee源,为了在国内网络环境更快下载,此处使用gitee源。
#! git clone https://github.com/PaddlePaddle/PaddleSeg.git
! git clone https://gitee.com/paddlepaddle/PaddleSeg.git
%cd ~/PaddleSeg/
#通过pip形式安装paddleseg库,不仅安装了代码运行的环境依赖,也安装了PaddleSeg的API
! pip install paddleseg
执行下面命令,并在PaddleSeg/output文件夹中出现预测结果,则证明安装成功
! python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams\
--image_path docs/images/optic_test_image.jpg \
--save_dir output/result
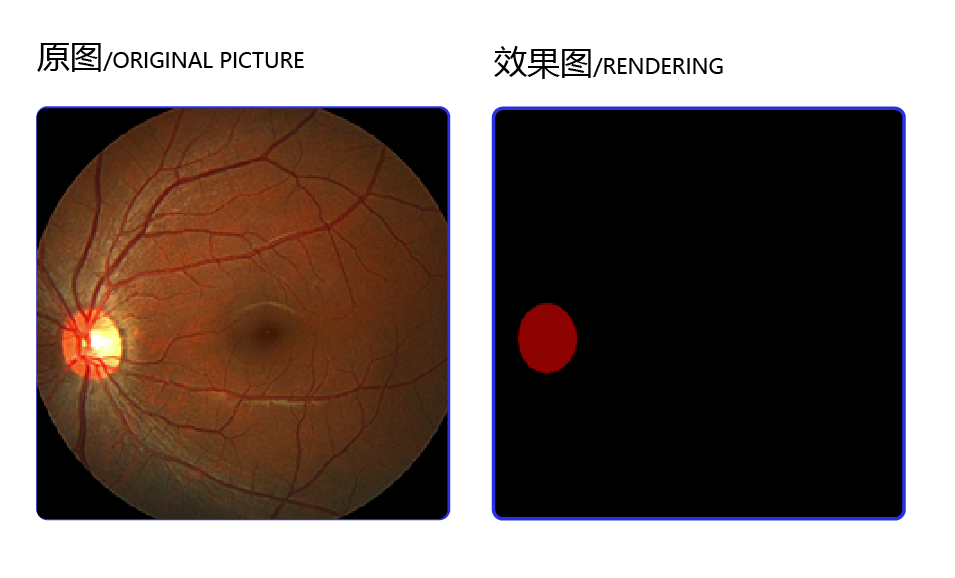
本章节将使用视盘分割(optic disc segmentation)数据集进行训练,视盘分割是一组眼底医疗分割数据集,包含了267张训练图片、76张验证图片、38张测试图片。通过以下命令可以下载该数据集。
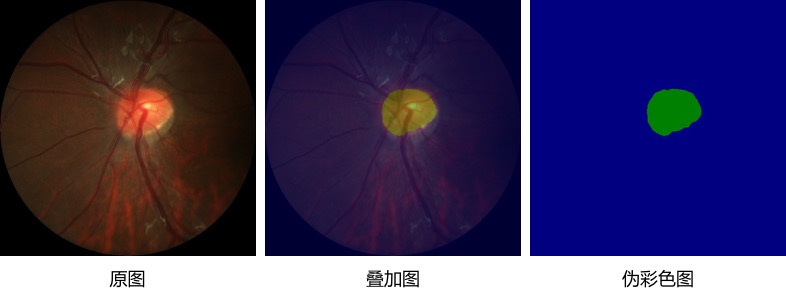
数据集的原图和效果图如下所示,任务是将眼球图片中的视盘区域分割出来。
图5:数据集的原图和效果图
#下载并解压数据集
! mkdir dataset
%cd dataset
! wget https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip
! unzip optic_disc_seg.zip
%cd ..
如何使用自己的数据集进行训练是开发者最关心的事情,下面我们将着重说明一下如果要自定义数据集,我们该准备成什么样子?数据集准备好,如何在配置文件中进行改动。
推荐整理成如下结构
文件夹命名为custom_dataset、images、labels不是必须,用户可以自主进行命名。
train.txt val.txt test.txt中文件并非要和custom_dataset文件夹在同一目录下,可以通过配置文件中的选项修改,但一般推荐整理成如下格式:
custom_dataset | |--images | |--image1.jpg | |--image2.jpg | |--... | |--labels | |--label1.png | |--label2.png | |--... | |--train.txt | |--val.txt | |--test.txt
其中train.txt和val.txt的内容如下所示:
images/image1.jpg labels/label1.png
images/image2.jpg labels/label2.png
...
我们刚刚下载的数据集格式也与之类似(label.txt可有可以无),如果用户要进行数据集标注和数据划分,请参考文档。
我们一般推荐用户将数据集放置在PaddleSeg下的dataset文件夹下。
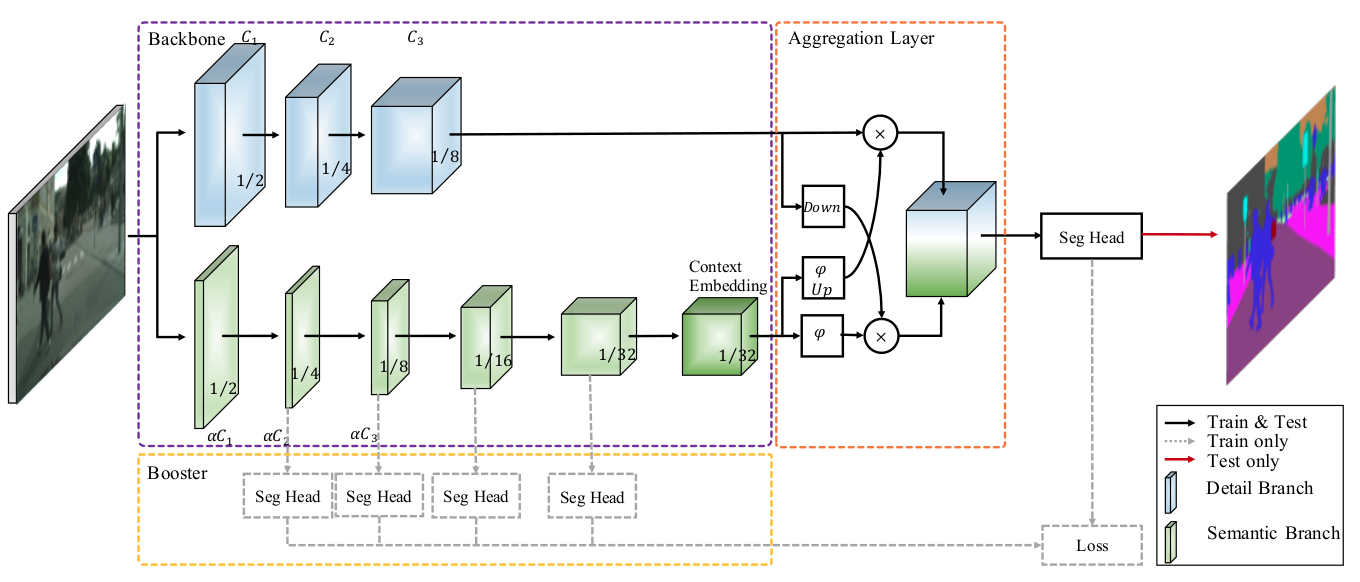
双边分割网络(BiSeNet V2),将低层次的网络细节和高层次的语义分类分开处理,以实现高精度和高效率的实时语义分割。它在速度和精度之间进行权衡。该体系结构包括:
(1)一个细节分支,具有浅层宽通道,用于捕获低层细节并生成高分辨率的特征表示。
(2)一个语义分支,通道窄,层次深,获取高层次语义语境。语义分支是轻量级的,因为它减少了通道容量和快速下采样策略。此外,设计了一个引导聚合层来增强相互连接和融合这两种类型的特征表示。此外,还设计了一种增强型训练策略,在不增加任何推理代价的情况下提高分割性能。
图6:数据集的原图和效果图
在了解完BiseNetV2原理后,我们便可准备进行训练了。上文中我们谈到PaddleSeg提供了配置化驱动进行模型训练。那么在训练之前,先来了解一下配置文件,在这里我们以bisenet_optic_disc_512x512_1k.yml为例子说明,该yaml格式配置文件包括模型类型、骨干网络、训练和测试、预训练数据集和配套工具(如数据增强)等信息。
PaddleSeg在配置文件中详细列出了每一个可以优化的选项,用户只要修改这个配置文件就可以对模型进行定制(所有的配置文件在PaddleSeg/configs文件夹下面),如自定义模型使用的骨干网络、模型使用的损失函数以及关于网络结构等配置。除了定制模型之外,配置文件中还可以配置数据处理的策略,如改变尺寸、归一化和翻转等数据增强的策略。
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大
iters: 1000 #模型迭代的次数
train_dataset: #训练数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #送入网络之前需要进行resize
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: RandomHorizontalFlip #采用水平反转的方式进行数据增强
- type: Normalize #图像进行归一化
mode: train
val_dataset: #验证数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #将原图resize成512*512在送入网络
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: Normalize #图像进行归一化
mode: val
optimizer: #设定优化器的类型
type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
learning_rate: #设定学习率
value: 0.01 #初始学习率
decay:
type: poly #采用poly作为学习率衰减方式。
power: 0.9 #衰减率
end_lr: 0 #最终学习率
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #损失函数类型
coef: [1, 1, 1, 1, 1]
#BiseNetV2有4个辅助loss,加上主loss共五个,1表示权重 all_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: BiSeNetV2 #设定模型类别
pretrained: Null #设定模型的预训练模型
FAQ
Q:有的读者可能会有疑问,什么样的配置项是设计在配置文件中,什么样的配置项在脚本的命令行参数呢?
A:与模型方案相关的信息均在配置文件中,还包括对原始样本的数据增强策略等。除了iters、batch_size、learning_rate3种常见参数外,命令行参数仅涉及对训练过程的配置。也就是说,配置文件最终决定了使用什么模型。
当用户准备好数据集后,可以在配置文件中指定位置修改数据路径来进行进一步的训练
在这里,我们还是以上文中谈到的"bisenet_optic_disc_512x512_1k.yml"文件为例,摘选出数据配置部分为大家说明。
主要关注这几个参数:
train_dataset:
type: Dataset
dataset_root: dataset/optic_disc_seg
train_path: dataset/optic_disc_seg/train_list.txt
num_classes: 2
transforms:
- type: Resize
target_size: [512, 512]
- type: RandomHorizontalFlip
- type: Normalize
mode: train
val_dataset:
type: Dataset
dataset_root: dataset/optic_disc_seg
val_path: dataset/optic_disc_seg/val_list.txt
num_classes: 2
transforms:
- type: Resize
target_size: [512, 512]
- type: Normalize
mode: val
当我们修改好对应的配置参数后,就可以上手体验使用了
In [6]
!export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡
# windows下请执行以下命令
# set CUDA_VISIBLE_DEVICES=0
!python train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
output
├── iter_500 #表示在500步保存一次模型
├── model.pdparams #模型参数
└── model.pdopt #训练阶段的优化器参数
├── iter_1000
├── model.pdparams
└── model.pdopt
└── best_model #在训练的时候,训练时候增加--do_eval后,每保存一次模型,都会eval一次,miou最高的模型会被另存为best_model
└── model.pdparams
| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| iters | 训练迭代次数 | 否 | 配置文件中指定值 |
| batch_size | 单卡batch size | 否 | 配置文件中指定值 |
| learning_rate | 初始学习率 | 否 | 配置文件中指定值 |
| config | 配置文件 | 是 | - |
| save_dir | 模型和visualdl日志文件的保存根路径 | 否 | output |
| num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 0 |
| use_vdl | 是否开启visualdl记录训练数据 | 否 | 否 |
| save_interval_iters | 模型保存的间隔步数 | 否 | 1000 |
| do_eval | 是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model | 否 | 否 |
| log_iters | 打印日志的间隔步数 | 否 | 10 |
| resume_model | 恢复训练模型路径,如:output/iter_1000
|
否 | None |
| keep_checkpoint_max | 最新模型保存个数 | 否 | 5 |
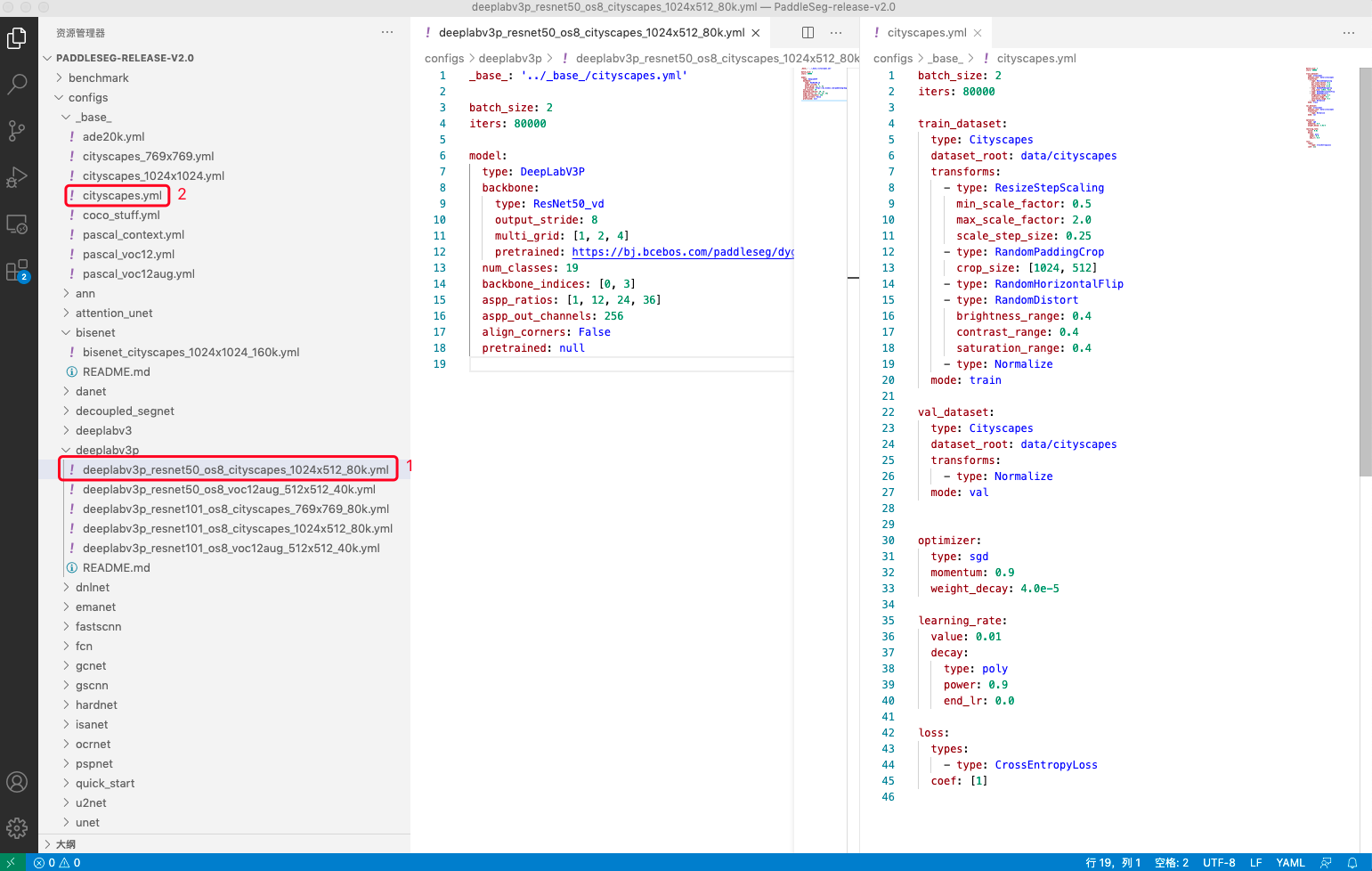
图7:配置文件深入探索
在PaddleSeg2.0模式下,用户可以发现,PaddleSeg采用了更加耦合的配置设计,将数据、优化器、损失函数等共性的配置都放在了一个单独的配置文件下面,当我们尝试换新的网络结构的是时候,只需要关注模型切换即可,避免了切换模型重新调节这些共性参数的繁琐节奏,避免用户出错。
FAQ
Q:有些共同的参数,多个配置文件下都有,那么我以哪一个为准呢?
A:如图中序号所示,1号yml文件的参数可以覆盖2号yml文件的参数,即1号的配置文件优于2号文件
注意:如果想要使用多卡训练的话,需要将环境变量CUDA_VISIBLE_DEVICES指定为多卡(不指定时默认使用所有的gpu),并使用paddle.distributed.launch启动训练脚本(windows下由于不支持nccl,无法使用多卡训练):
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 设置4张可用的卡
python -m paddle.distributed.launch train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
python train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--resume_model output/iter_500 \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
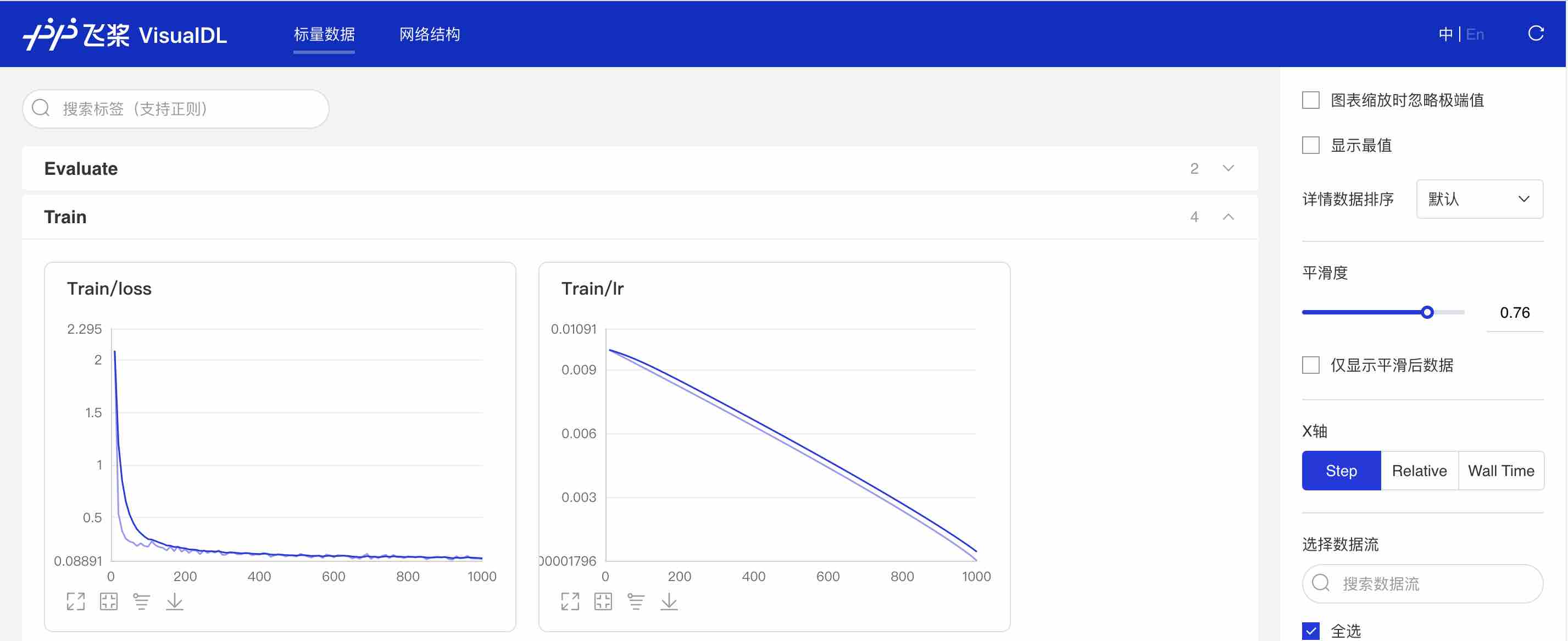
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
do_eval开关后生效)do_eval开关后生效)使用如下命令启动VisualDL查看日志
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
visualdl --logdir output/
在浏览器输入提示的网址,效果如下:
图8:VDL效果演示
训练完成后,用户可以使用评估脚本val.py来评估模型效果。假设训练过程中迭代次数(iters)为1000,保存模型的间隔为500,即每迭代1000次数据集保存2次训练模型。因此一共会产生2个定期保存的模型,加上保存的最佳模型best_model,一共有3个模型,可以通过model_path指定期望评估的模型文件。
!python val.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams
如果想进行多尺度翻转评估可通过传入--aug_eval进行开启,然后通过--scales传入尺度信息, --flip_horizontal开启水平翻转, flip_vertical开启垂直翻转。使用示例如下:
python val.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--aug_eval \
--scales 0.75 1.0 1.25 \
--flip_horizontal
如果想进行滑窗评估可通过传入--is_slide进行开启, 通过--crop_size传入窗口大小, --stride传入步长。使用示例如下:
python val.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--is_slide \
--crop_size 256 256 \
--stride 128 128
在图像分割领域中,评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
Kappa=P0−Pe1−PeKappa= \frac{P_0-P_e}{1-P_e}Kappa=1−PeP0−P**e
随着评估脚本的运行,最终打印的评估日志如下。
...
2021-01-13 16:41:29 [INFO] Start evaluating (total_samples=76, total_iters=76)...
76/76 [==============================] - 2s 30ms/step - batch_cost: 0.0268 - reader cost: 1.7656e-
2021-01-13 16:41:31 [INFO] [EVAL] #Images=76 mIoU=0.8526 Acc=0.9942 Kappa=0.8283
2021-01-13 16:41:31 [INFO] [EVAL] Class IoU:
[0.9941 0.7112]
2021-01-13 16:41:31 [INFO] [EVAL] Class Acc:
[0.9959 0.8886]
除了分析模型的IOU、ACC和Kappa指标之外,我们还可以查阅一些具体样本的切割样本效果,从Bad Case启发进一步优化的思路。
predict.py脚本是专门用来可视化预测案例的,命令格式如下所示
In [8]
!python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg \
--save_dir output/result
其中image_path也可以是一个目录,这时候将对目录内的所有图片进行预测并保存可视化结果图。
同样的,可以通过--aug_pred开启多尺度翻转预测, --is_slide开启滑窗预测。
我们选择1张图片进行查看,效果如下。我们可以直观的看到模型的切割效果和原始标记之间的差别,从而产生一些优化的思路,比如是否切割的边界可以做规则化的处理等。
图9:预测效果展示
为了方便用户进行工业级的部署,PaddleSeg提供了一键动转静的功能,即将训练出来的动态图模型文件转化成静态图形式。
! python export.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams
| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| config | 配置文件 | 是 | - |
| save_dir | 模型和visualdl日志文件的保存根路径 | 否 | output |
| model_path | 预训练模型参数的路径 | 否 | 配置文件中指定值 |
output
├── deploy.yaml # 部署相关的配置文件
├── model.pdiparams # 静态图模型参数
├── model.pdiparams.info # 参数额外信息,一般无需关注
└── model.pdmodel # 静态图模型文件
| 端侧 | 库 | 教程 |
|---|---|---|
| Python端部署 | Paddle预测库 | 已完善 |
| 移动端部署 | ONNX | 完善中 |
| 服务端部署 | HubServing | 完善中 |
| 前端部署 | PaddleJS | 完善中 |
#运行如下命令,会在output文件下面生成一张H0003.png的图像
!python deploy/python/infer.py \
--config output/deploy.yaml\
--image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg\
--save_dir output
| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| config | 导出模型时生成的配置文件, 而非configs目录下的配置文件 | 是 | - |
| image_path | 预测图片的路径或者目录 | 是 | - |
| use_trt | 是否开启TensorRT来加速预测 | 否 | 否 |
| use_int8 | 启动TensorRT预测时,是否以int8模式运行 | 否 | 否 |
| batch_size | 单卡batch size | 否 | 配置文件中指定值 |
| save_dir | 保存预测结果的目录 | 否 | output |
PaddleSeg
├── configs #配置文件文件夹
├── paddleseg #训练部署的核心代码
├── core
├── cvlibs # Config类定义在该文件夹中。它保存了数据集、模型配置、主干网络、损失函数等所有的超参数。
├── callbacks.py
└── ...
├── datasets #PaddleSeg支持的数据格式,包括ade、citycapes等多种格式
├── ade.py
├── citycapes.py
└── ...
├── models #该文件夹下包含了PaddleSeg组网的各个部分
├── backbone # paddleseg的使用的主干网络
├── hrnet.py
├── resnet_vd.py
└── ...
├── layers # 一些组件,例如attention机制
├── activation.py
├── attention.py
└── ...
├── losses #该文件夹下包含了PaddleSeg所用到的损失函数
├── dice_loss.py
├── lovasz_loss.py
└── ...
├── ann.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示ann算法。
├── deeplab.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示Deeplab算法。
├── unet.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示unet算法。
└── ...
├── transforms #进行数据预处理的操作,包括各种数据增强策略
├── functional.py
└── transforms.py
└── utils
├── config_check.py
├── visualize.py
└── ...
├── train.py # 训练入口文件,该文件里描述了参数的解析,训练的启动方法,以及为训练准备的资源等。
├── predict.py # 预测文件
└── ...
PaddleSeg等各领域的开发套件已经为真正的工业实践提供了顶级方案,有国内的团队使用PaddleSeg的开发套件取得国际比赛的好成绩,可见开发套件提供的效果是State Of The Art的。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。