

代码拉取完成,页面将自动刷新
title: Mysql 应用指南
date: 2020-07-13 10:08:37
categories:
- 数据库
- 关系型数据库
- Mysql
tags:
- 数据库
- 关系型数据库
- Mysql
permalink: /pages/5fe0f3/
学习 Mysql,最好是先从宏观上了解 Mysql 工作原理。
参考:Mysql 工作流
在文件系统中,Mysql 将每个数据库(也可以成为 schema)保存为数据目录下的一个子目录。创建表示,Mysql 会在数据库子目录下创建一个和表同名的 .frm 文件保存表的定义。因为 Mysql 使用文件系统的目录和文件来保存数据库和表的定义,大小写敏感性和具体平台密切相关。Windows 中大小写不敏感;类 Unix 中大小写敏感。不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在 Mysql 服务层统一处理的。
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
大多数情况下,InnoDB 都是正确的选择,除非需要用到 InnoDB 不具备的特性。
如果应用需要选择 InnoDB 以外的存储引擎,可以考虑以下因素:
下面的语句可以将 mytable 表的引擎修改为 InnoDB
ALTER TABLE mytable ENGINE = InnoDB
MyISAM 设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用 MyISAM。
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录的地址。
MyISAM 提供了大量的特性,包括:全文索引、压缩表、空间函数等。但是,MyISAM 不支持事务和行级锁。并且 MyISAM 不支持崩溃后的安全恢复。
InnoDB 是 MySQL 默认的事务型存储引擎,只有在需要 InnoDB 不支持的特性时,才考虑使用其它存储引擎。
然 InnoDB 也使用 B+Tree 作为索引结构,但具体实现方式却与 MyISAM 截然不同。MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在 InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此InnoDB 表数据文件本身就是主索引。
InnoDB 采用 MVCC 来支持高并发,并且实现了四个标准的隔离级别。其默认级别是可重复读(REPEATABLE READ),并且通过间隙锁(next-key locking)防止幻读。
InnoDB 是基于聚簇索引建立的,与其他存储引擎有很大不同。在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 32, 64 位存储空间,一般情况下越小的列越好。
UNSIGNED 表示不允许负值,大致可以使正数的上限提高一倍。
INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
FLOAT 和 DOUBLE 为浮点类型。
DECIMAL 类型主要用于精确计算,代价较高,应该尽量只在对小数进行精确计算时才使用 DECIMAL ——例如存储财务数据。数据量比较大的时候,可以使用 BIGINT 代替 DECIMAL。
FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。
VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长。当超出一个页所能容纳的大小时,就要执行额外的操作。MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内。
VARCHAR 会保留字符串末尾的空格,而 CHAR 会删除。
MySQL 提供了两种相似的日期时间类型:DATATIME 和 TIMESTAMP。
能够保存从 1001 年到 9999 年的日期和时间,精度为秒,使用 8 字节的存储空间。
它与时区无关。
默认情况下,MySQL 以一种可排序的、无歧义的格式显示 DATATIME 值,例如“2008-01-16 22:37:08”,这是 ANSI 标准定义的日期和时间表示方法。
和 UNIX 时间戳相同,保存从 1970 年 1 月 1 日午夜(格林威治时间)以来的秒数,使用 4 个字节,只能表示从 1970 年 到 2038 年。
它和时区有关,也就是说一个时间戳在不同的时区所代表的具体时间是不同的。
MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
BLOB 和 TEXT 都是为了存储大的数据而设计,前者存储二进制数据,后者存储字符串数据。
不能对 BLOB 和 TEXT 类型的全部内容进行排序、索引。
大多数情况下没有使用枚举类型的必要,其中一个缺点是:枚举的字符串列表是固定的,添加和删除字符串(枚举选项)必须使用ALTER TABLE(如果只只是在列表末尾追加元素,不需要重建表)。
整数类型通常是标识列最好的选择,因为它们很快并且可以使用 AUTO_INCREMENT。
ENUM 和 SET 类型通常是一个糟糕的选择,应尽量避免。
应该尽量避免用字符串类型作为标识列,因为它们很消耗空间,并且通常比数字类型慢。对于 MD5、SHA、UUID 这类随机字符串,由于比较随机,所以可能分布在很大的空间内,导致 INSERT 以及一些 SELECT 语句变得很慢。
- 符号;更好的做法是,用 UNHEX() 函数转换 UUID 值为 16 字节的数字,并存储在一个 BINARY(16) 的列中,检索时,可以通过 HEX() 函数来格式化为 16 进制格式。详见:Mysql 索引
详见:Mysql 锁
详见:Mysql 事务
详见:Mysql 性能优化
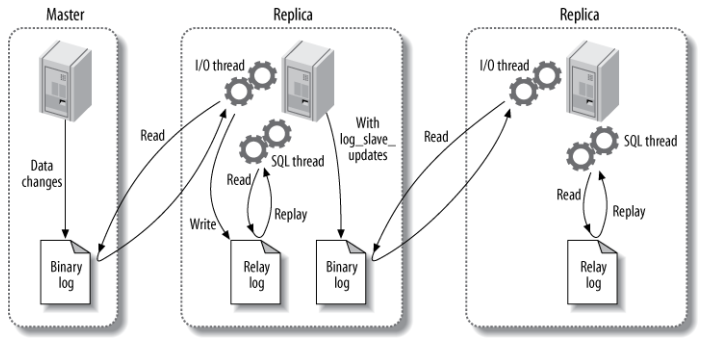
Mysql 支持两种复制:基于行的复制和基于语句的复制。
这两种方式都是在主库上记录二进制日志,然后在从库重放日志的方式来实现异步的数据复制。这意味着:复制过程存在时延,这段时间内,主从数据可能不一致。
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
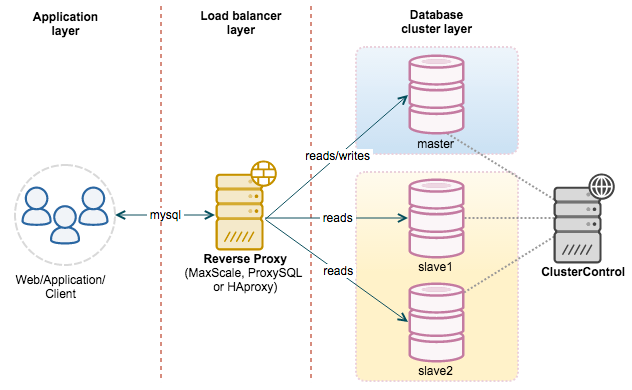
主服务器用来处理写操作以及实时性要求比较高的读操作,而从服务器用来处理读操作。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
MySQL 读写分离能提高性能的原因在于:
◾ 💧 钝悟的 IT 知识图谱 ◾ 🎯 钝悟的博客 ◾
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





