

代码拉取完成,页面将自动刷新
title: Redis 面试总结
date: 2020-07-13 17:03:42
categories:
- 数据库
- KV数据库
- Redis
tags:
- 数据库
- KV数据库
- Redis
- 面试
permalink: /pages/451b73/
【问题】
【解答】
Redis 数据类型和应用
数据类型的特性和应用细节点较多,详情可以参考:Redis 数据类型
(1)Redis 支持五种基本数据类型:
(2)除此以外,还有 Bitmaps、HyperLogLogs、GEO、Streams 等高级数据类型。
【问题】
【解答】
(1)Redis 过期策略是:定期删除+惰性删除。
(2)Redis 内存淘汰策略:
noeviction - 当内存使用达到阈值的时候,所有引起申请内存的命令会报错。这是 Redis 默认的策略。allkeys-lru - 在主键空间中,优先移除最近未使用的 key。allkeys-random - 在主键空间中,随机移除某个 key。volatile-lru - 在设置了过期时间的键空间中,优先移除最近未使用的 key。volatile-random - 在设置了过期时间的键空间中,随机移除某个 key。volatile-ttl - 在设置了过期时间的键空间中,具有更早过期时间的 key 优先移除。(3)如何选择内存淘汰策略:
allkeys-lru。allkeys-random。volatile-lru 策略和 volatile-random 策略适合我们将一个 Redis 实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个 Redis 实例来达到相同的效果。allkeys-lru 策略从而更有效率的使用内存。(4)LRU 算法实现思路:可以继承 LinkedHashMap,并覆写 removeEldestEntry 方法来实现一个最简单的 LRUCache
【问题】
【解答】
Redis 持久化
详情可以参考:Redis 持久化
(1)Redis 支持两种持久化方式:RDB 和 AOF。
(2)RDB 即某一时刻的二进制数据快照。
Redis 会周期性生成 RDB 文件。
生成 RDB 流程:Redis fork 一个子进程,负责生成 RDB;生成 RDB 采用 Copy On Write 模式,此时,如果收到写请求,会在原副本上操作,不影响工作。
RDB 只能恢复生成快照时刻的数据,之后的数据无法恢复。生成 RDB 的资源开销高昂。RDB 适合做冷备。
(3)AOF 会将写命令不断追加到 AOF 文本日志末尾。
AOF 丢数据比 RDB 少,但文件会比 RDB 文件大很多。
一般,AOF 设置 appendfsync 同步频率为 everysec 即可。
(4)RDB or AOF
建议同时使用 RDB 和 AOF。用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
【问题】
【解答】
Redis 的事务特性、原理
详情参考:Redis 应用指南之 事务
Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
Redis 不支持回滚的理由:
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。
Redis 有天然解决这个并发竞争问题的类 CAS 乐观锁方案:每次要写之前,先判断一下当前这个 value 的时间戳是否比缓存里的 value 的时间戳要新。如果是的话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
【问题】
【解答】
Redis 是一种基于 C/S 模型以及请求/响应协议的 TCP 服务。Redis 支持管道技术。管道技术允许请求以异步方式发送,即旧请求的应答还未返回的情况下,允许发送新请求。这种方式可以大大提高传输效率。使用管道发送命令时,Redis Server 会将部分请求放到缓存队列中(占用内存),执行完毕后一次性发送结果。如果需要发送大量的命令,会占用大量的内存,因此应该按照合理数量分批次的处理。
【问题】
【解答】
Redis 集群
详情可以参考:Redis 集群
(1)单线程
Redis 为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis 单机吞吐量也很高,能达到几万 QPS。
Redis 单线程模型,依然有很高的并发吞吐,原因在于:
(2)扩展并发吞吐量、存储容量
Redis 的高性能(扩展并发吞吐量、存储容量)通过主从架构来实现。
Redis 集群采用主从模型,提供复制和故障转移功能,来保证 Redis 集群的高可用。通常情况,一主多从模式已经可以满足大部分项目的需要。根据实际的并发量,可以通过增加节点来扩展并发吞吐。
一主多从模式下,主节点负责写操作(单机几万 QPS),从节点负责查询操作(单机十万 QPS)。
进一步,如果需要缓存大量数据,就需要分区(sharding)。Redis 集群通过划分虚拟 hash 槽来分片,每个主节点负责一定范围的 hash 槽。当需要扩展集群节点时,重新分配 hash 槽即可,redis-trib 会自动迁移变更 hash 槽中所属的 key。
(3)Redis 集群数据一致性
Redis 集群基于复制特性实现节点间的数据一致性。
【问题】
【解答】
Redis 复制
详情可以参考:Redis 复制
(1)旧版复制基于 SYNC 命令实现。分为同步(sync)和命令传播(command propagate)两个操作。这种方式存在缺陷:不能高效处理断线重连后的复制情况。
(2)新版复制基于 PSYNC 命令实现。同步操作分为了两块:
完整重同步(full resychronization) 用于初次复制;部分重同步(partial resychronization) 用于断线后重复制。
(3)Redis 集群主从节点复制的工作流程:
【问题】
【解答】
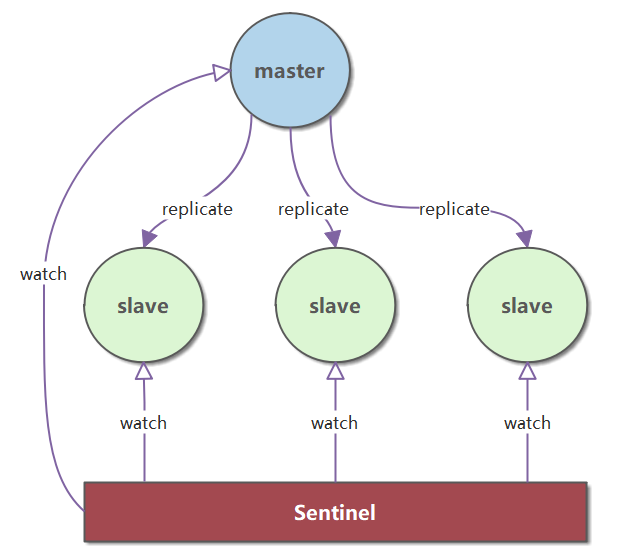
Redis 哨兵
详情可以参考:Redis 哨兵
(1)Redis 的高可用是通过哨兵来实现(Raft 协议的 Redis 实现)。Sentinel(哨兵)可以监听主服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
【问题】
Redis 和 Memcached 有什么区别?
分布式缓存技术选型,选 Redis 还是 Memcached,为什么?
Redis 和 Memcached 各自的线程模型是怎样的?
为什么单线程的 Redis 性能却不输于多线程的 Memcached?
【解答】
Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。memcache 支持简单的数据类型,String。
Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中
redis 的速度比 memcached 快很多
Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的 IO 复用模型。
如果想要更详细了解的话,可以查看慕课网上的这篇手记(非常推荐) :《脚踏两只船的困惑 - Memcached 与 Redis》:www.imooc.com/article/23549
终极策略: 使用 Redis 的 String 类型做的事,都可以用 Memcached 替换,以此换取更好的性能提升; 除此以外,优先考虑 Redis;
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





