

代码拉取完成,页面将自动刷新
同步操作将从 xtuhcy/Gecco 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。


Gecco是一款用java语言开发的轻量化的易用的网络爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。同时Gecco基于十分开放的MIT开源协议,无论你是使用者还是希望共同完善Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请star 或者 fork!
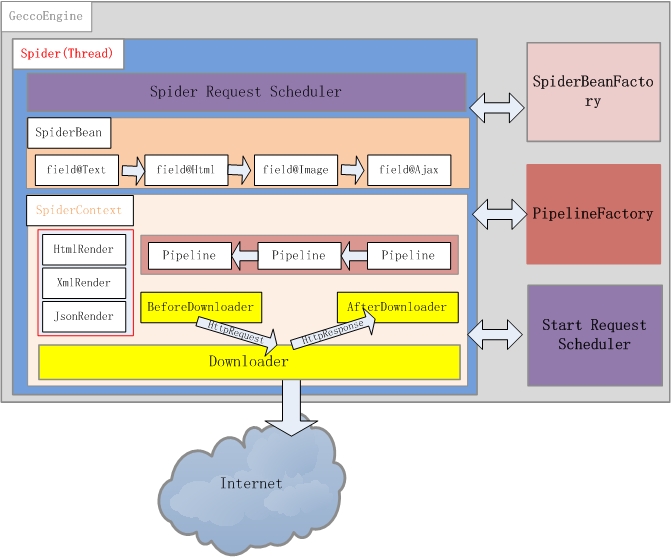
GeccoEngine是爬虫引擎,每个爬虫引擎最好是一个独立进程,在分布式爬虫场景下,建议每台爬虫服务器(物理机或者虚机)运行一个GeccoEngine。爬虫引擎包括Scheduler、Downloader、Spider、SpiderBeanFactory、PipelineFactory5个主要模块。
通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略。
Downloader负责从Scheduler中获取需要下载的请求,gecco默认采用httpclient4.x作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎。你也可以对每个请求定义BeforeDownload和AfterDownload,实现不同的请求下载的个性需求。
Gecco将下载下来的内容渲染为SpiderBean,所有爬虫渲染的JavaBean都统一继承SpiderBean,SpiderBean又分为HtmlBean和JsonBean分别对应html页面的渲染和json数据的渲染。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext。上下文SpiderBeanContext会告知这个SpiderBean采用什么渲染器,采用那个下载器,渲染完成后采用哪些pipeline处理等相关上下文信息。
pipeline是SpiderBean渲染完成的后续业务处理单元,PipelineFactory是pipeline的工厂类,负责pipeline实例化。通过扩展PipelineFactory就可以实现和Spring等业务处理框架的整合。
Gecco框架最核心的类应该是Spider线程,一个爬虫引擎可以同时运行多个Spider线程。Spider描绘了这个框架运行的基本骨架,先从Scheduler获取请求,再通过SpiderBeanFactory匹配SpiderBeanClass,再通过SpiderBeanClass找到SpiderBean的上下文,下载网页并对SpiderBean做渲染,将渲染后的SpiderBean交个pipeline处理。
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>x.x.x</version>
</dependency>
httpclient,jsoup,fastjson,reflections,cglib,rhino,log4j,jmxutils,commons-lang3
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -7127412585200687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("https://github.com/xtuhcy/gecco")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//非阻塞方式运行
.start();
}
}
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热部署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的例子。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("https://github.com/{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://github.com/xtuhcy/gecco")
.run();
可以看到,DynamicGecco的方式相比传统的注解方式代码量大大减少,而且很酷的一点是DynamicGecco支持运行时定义和修改规则。
Gecco的发展离不开大家支持,扫一扫请作者喝杯咖啡~


请遵守开源协议MIT
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





